Pandas is a Python package providing fast, flexible, and expressive data structures designed to work with relational or labeled data both. It is a fundamental high-level building block for doing practical, real world data analysis in Python.




 Understand the Titanic dataset
Understand the Titanic dataset
 Query with Filter Condition/Sort the dataset
Query with Filter Condition/Sort the dataset
 Dropping not required columns and rows. Selecting specific features for analysis as shown below
Dropping not required columns and rows. Selecting specific features for analysis as shown below
 Applying data operations with different statistical functions and using the groupby functions
Applying data operations with different statistical functions and using the groupby functions

Pandas is well suited for:
- Tabular data with heterogeneously-typed columns, as in an SQL table or Excel spreadsheet
- Ordered and unordered (not necessarily fixed-frequency) time series data.
- Arbitrary matrix data (homogeneously typed or heterogeneous) with row and column labels
- Any other form of observational / statistical data sets. The data actually need not be labeled at all to be placed into a pandas data structure
Key features:
- Easy handling of missing data
- Size mutability: columns can be inserted and deleted from DataFrame and higher dimensional objects
- Automatic and explicit data alignment: objects can be explicitly aligned to a set of labels, or the data can be aligned automatically
- Powerful, flexible group by functionality to perform split-apply-combine operations on data sets
- Intelligent label-based slicing, fancy indexing, and subsetting of large data sets
- Intuitive merging and joining data sets
- Flexible reshaping and pivoting of data sets
- Hierarchical labeling of axes
- Robust IO tools for loading data from flat files, Excel files, databases, and HDF5
- Time series functionality: date range generation and frequency conversion, moving window statistics, moving window linear regressions, date shifting and lagging, etc.
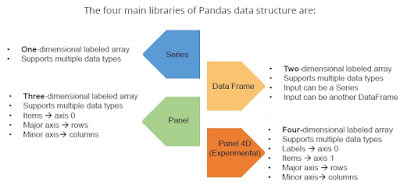
Pandas Data structure:-

Series:-
The Series data structure in Pandas is a one-dimensional labeled array.
- Data in the array can be of any type (integers, strings, floating point numbers, Python objects, etc.).
- Data within the array is homogeneous
- Pandas Series objects are amphibian in character, exhibiting both ndarray-like and dict-like properties.
There are many ways to create a Pandas Series objects, some of the most common ways are:
Creating, retrieval of element in series from a list,

Creating, retrieval of elements in series from a dictionary

DataFrame is a 2-dimensional labeled data structure with columns of potentially different types. You can think of it like a spreadsheet or SQL table, or a dict of Series objects. It is generally the most commonly used pandas object. Like Series, DataFrame accepts many different kinds of input:
- Dict of 1D ndarrays, lists, dicts, or Series
- 2-D numpy.ndarray
- Structured or record ndarray
- A Series
- Another DataFrame

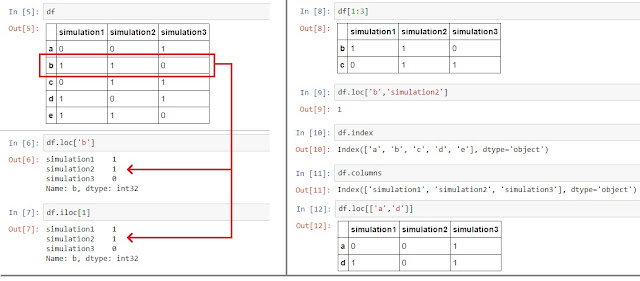
The basics of indexing / row selection
Data can be accessed through different functions like loc, ilocby passing data element position or index range.


In this seccion we review some of the most commonly used functions when doing data analysis with pandas. Data operation can be performed through various built-in methods for faster data processing.
Load a dataframe from a csv file
View few records to understand the data in a DataFrame





No comments:
Post a Comment
Note: only a member of this blog may post a comment.